Data Standards & Pipelines
What are Data Standards and Pipelines?
The GDR data standards and pipelines create consistency in formatting and contents of like datasets, lessening preprocessing requirements and ensuring adequate information is provided by a given dataset. Data standards and pipelines are different for each data type, in an attempt to best fit a given data type's formatting, metadata, and other requirements.
Existing Data Standards
The GDR's drilling data pipeline automatically converts drilling data from native Pason or RigCLOUD ouput format into a standardized CSV format with standardized column names and units.
The GDR's DAS data pipeline automatically converts DAS data from nonstandardized SEG-Y formats into a standardized HDF5 format, based on PRODML and the IRIS DAS RCN's DAS metadata standard.
The GDR's geospatial data pipeline focuses on metadata rather than the data itself. It automatically recognizes geospatial data files using file extensions, and requires additional and essential metadata for geospatial datasets.
Coming Soon
When the GDR is working on implementing a new data standard & pipeline, it will be listed here. If you have suggestions for new data standards and pipelines, please send them to GDR Help.
Tips to Ensure Your Data are Standardized
To ensure your data are standardized, follow these tips:
- Do not enclose your data in zipped directories. Instead upload files with their original file extensions to the GDR submission form or data lake.
- Do not modify the format of your files from the original export format before uploading to the GDR.
- Maximize the metadata you provide in the GDR submission form or via a README file. More is always better.
- Check out the more specific tips on each of the individual data standard pages linked under “Existing Data Standards” above.
If you think your dataset should have been standardized, but was not, please contact GDR Help. We are happy to assist and are constantly looking to improve are data standards and pipelines.
Acknowledgment
We'd like to acknowledge the National Geothermal Data System (NGDS) content models as the catalyst for this work on data standardization. The NGDS content models are now retired.
Why Standardize?

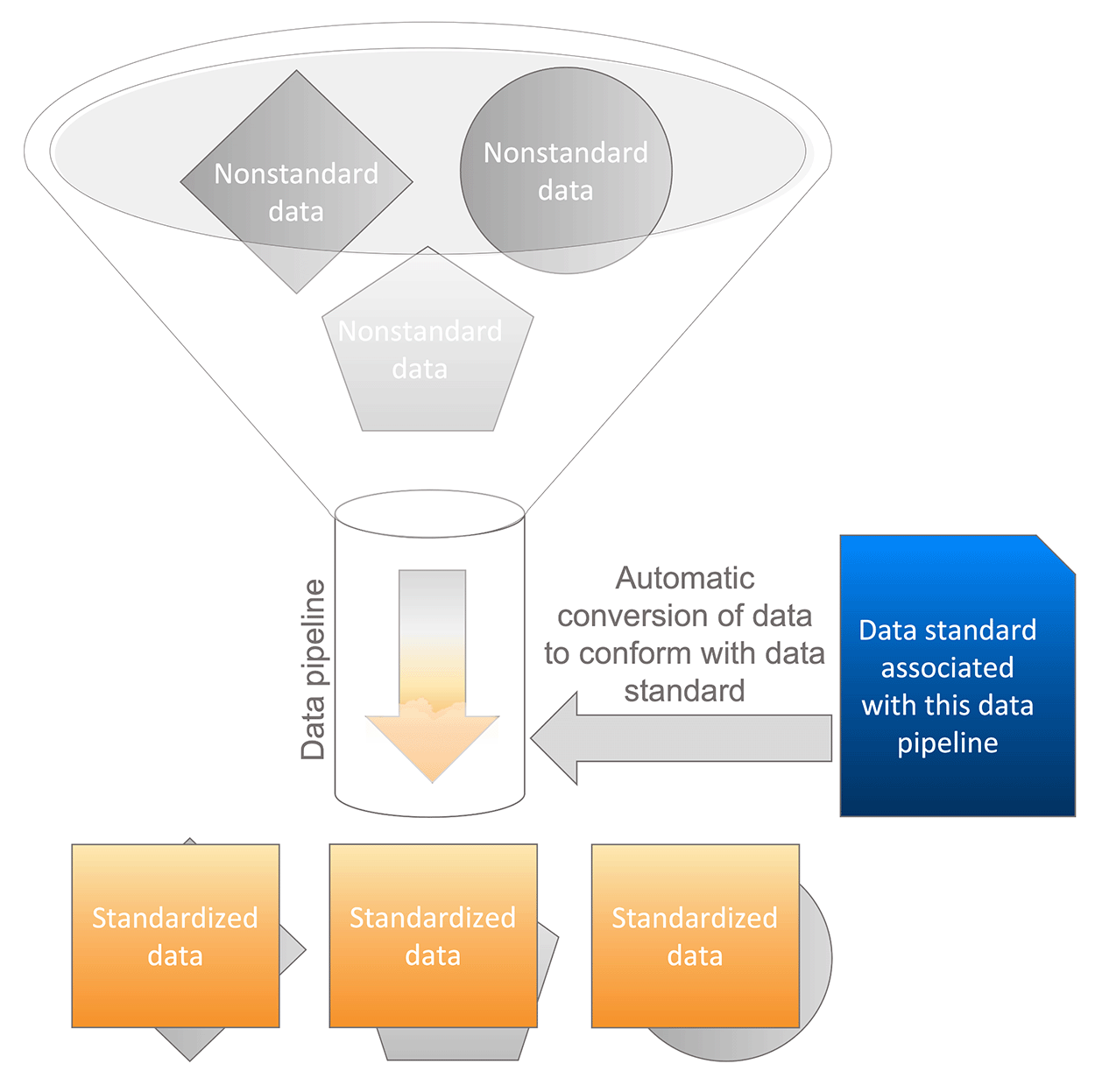
Automated Data Pipelines
Data pipelines have been implemented for select high-value data sets to automate the standardization process. The GDR's data pipelines automatically recognize certain types of datasets, and then convert them into a standardized format while also preserving the original data file. This shift takes the burden of data standardization off the user and project teams, allowing more project resources to be used on research and development activities, and increase the availability of standardized geothermal data available through the GDR. A set of recommendations and a data standard for each data type, will exist with each data pipeline in order to advise data collection for maximum usability for future research.
Learn More or Submit Feedback
If you want to learn more about the importance of data standardization for data science in geothermal, check out this Stanford Geothermal Workshop paper: Taverna, N., Weers, J., Huggins, J., Anderson, A., Frone, Z. “Improving the Quality of Geothermal Data Through Data Standards and Pipelines Within the Geothermal Data Repository (GDR).” Proceedings of the 48th Workshop on Geothermal Reservoir Engineering, Stanford Geothermal Program (2023).
The GDR team is continuously working to align its efforts with the needs of the geothermal community, and we would like to invite you to provide your feedback here: GDR.Help@nlr.gov.