Submitting Data to GDR Data Lakes
Submitting Big Data to GDR Data Lakes
GDR data lakes are well suited to data that is either too large to upload using the standard GDR submission form (i.e., greater than 1 TB), or especially complex (e.g., multi-dimensional time series data or data that is hierarchical in nature).
If you are unsure if your data are a good fit for storage in the GDR data lakes, please contact GDR Help.
Preferred Formats
The GDR does not require any specific formats, but recommends data be structured in cloud-optimized formats such as:
- HDF5 (utilizing cloud-optimized wrappers like HSDS or kerchunk)
- Parquet
- Geoparquet
- NetCDF (utilizing cloud-optimized wrappers like kerchunk)
Additional Requirements
To remain compliant with our open data partners, the following are required for data lake submissions in addition to the normal data submission form:
- A questionnaire that includes questions about the size, expected growth rate, anticipated update frequency, and a justification of the value of the dataset.
- A Jupyter notebook tutorial for how to work with and access the data.
- The GDR curation team will assist with the access portion of the notebook.
- An intuitive organizational structure for the data that enables users to parse these especially large and/or complex datasets, along with a Readme file that explains the organizational structure of the data.
- This structure should account for possible future versions of the data.
Benefits
The GDR data lakes provide centralized, cloud-based access to big, complex datasets. A few of the benefits include:
- Users can parse and access individual files without downloading the entire dataset.
- Users are able to use cloud-based tools to interact with data, allowing them to query or analyze the data without downloading it.
- Data are additionally advertised in our cloud providers' public dataset catalogs.
Updates to Existing Datasets
If you'd like to update an existing data lake submission, please contact GDR Help. The team will assist you in transferring the updated data files and updating the existing metadata. Please note that, once published, data in the GDR, including its data lakes, is generally considered permanent. Updates to existing datasets typically require the creation of a new version of the dataset to be hosted alongside previous versions for scientific posterity.
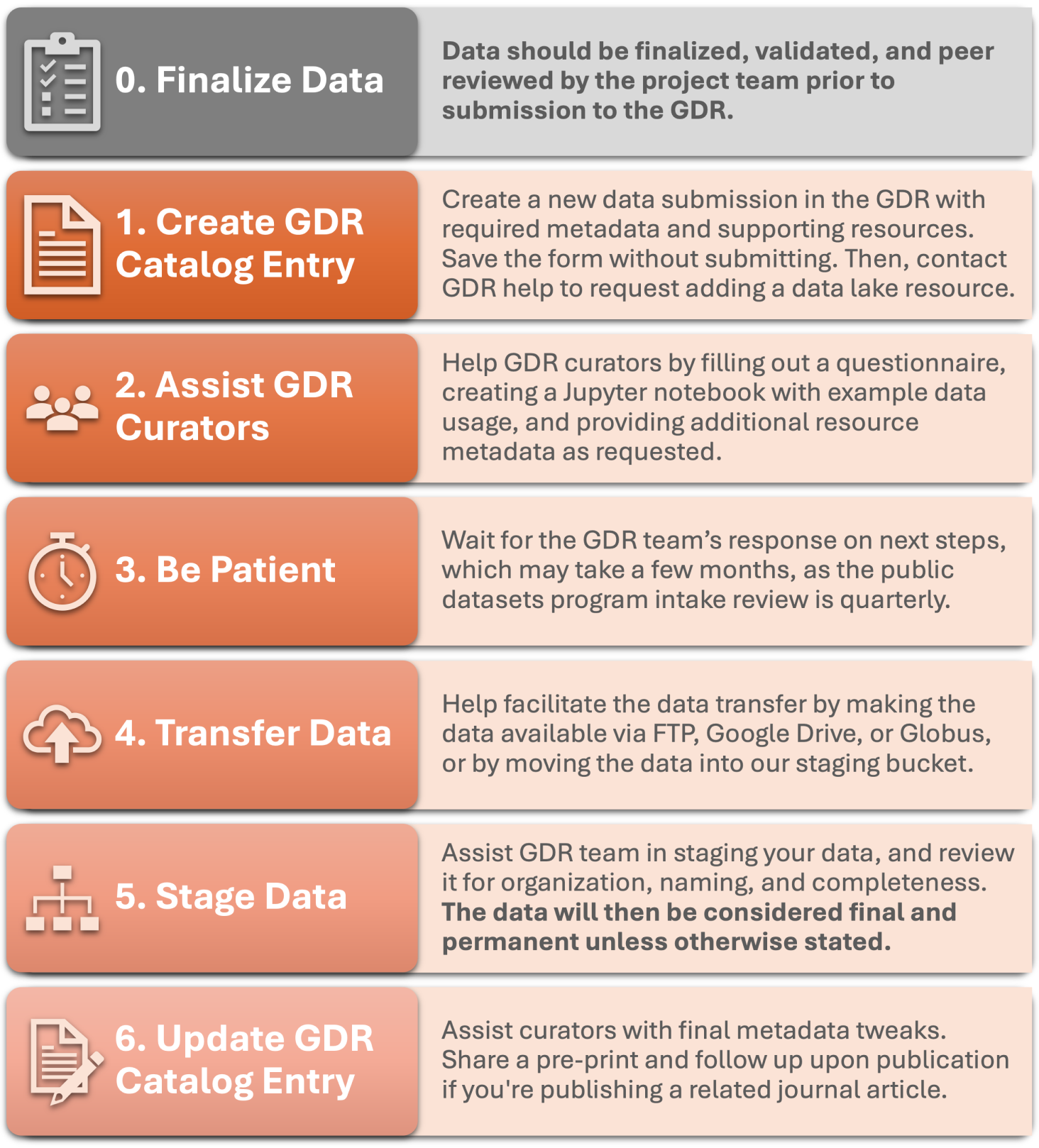
The Process